Accelerating Multimodal Model Training: A Deep Dive into LoongForge's DP Load Balancing Optimization
Official website: https://baidu-baige.github.io/LoongForge/
1. Data-parallel load imbalance limits overall multimodal model training efficiency
1.1. The performance bottleneck of DP gradient synchronization
Training large language models and multimodal large models commonly relies on Data Parallel (DP) distributed training. The core logic is to distribute training data to compute nodes; each node independently performs model forward and backward propagation, and then global parameter updates are unified through gradient synchronization operations such as AllReduce.
Therefore, overall distributed-training throughput and compute utilization depend not only on the compute performance of each single-node GPU, but also heavily on consistency in progress across all DP compute nodes. The nature of distributed synchronization means that a compute delay on any one node is amplified globally during gradient synchronization, creating redundant waiting for all participants and directly reducing training efficiency.
1.2. Inherent defects of fixed-length packing
To improve GPU utilization and avoid redundant invalid computation caused by sequence padding, industrial training workloads commonly use a fixed-length packing strategy. Training samples with different original lengths are concatenated into fixed-length packs, such as 32K / 64K / 128K, as input sequences. This keeps the total number of training tokens consistent across DP nodes and provides a basic form of load balancing from the token-count dimension.
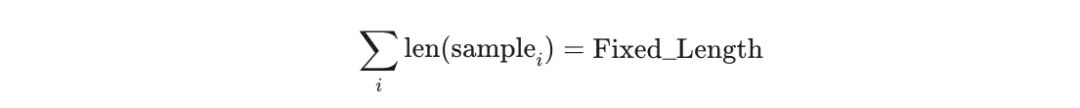
However, this strategy has a fundamental limitation: it cannot fit the real compute characteristics of Transformer models. The core attention mechanism in the Transformer architecture has compute complexity that grows quadratically with sequence length. This means that even if two DP nodes process exactly the same total number of tokens, any difference in the sample-length distribution inside the nodes can create a huge gap in actual core compute cost. Basic token-level load balancing is not equivalent to real compute-load balancing.
Take a 32K fixed-packing training configuration as an example. The input on DP 0 consists of eight short samples of length 4K, while the input on DP 1 consists of two long samples of length 16K. The two nodes process exactly the same total number of tokens, and the compute cost of the model's linear modules is basically comparable.
But because attention complexity is quadratic, the attention cost of long-sequence samples on DP 1 is greatly amplified, significantly increasing total forward and backward computation time. DP 0, dominated by short samples, has very low attention pressure and finishes the iteration quickly. As a result, under fixed-length packing, DP nodes still suffer from severe compute-load imbalance: nodes with short samples finish early and then wait a long time for nodes with long samples, causing global waiting overhead to accumulate.
1.3. The DP load-imbalance challenge in multimodal models
Compared with text-only large language models, the load-balancing problem in multimodal training is more complex and difficult. Multimodal training data contains text and image data, and image and video modalities themselves introduce significant load imbalance. Resolution differences between images directly lead to inconsistent compute; high-resolution images usually produce more patches or features and therefore higher compute and memory cost. The number of images in each sample may also differ, so multi-image samples cost more to encode than single-image samples. In video data, frame-count distributions are often highly uneven: long videos with many frames greatly lengthen forward and backward time, while short videos have much smaller compute cost.
For multimodal models, image resolution, image count, and video frame count all vary. Therefore, in addition to maintaining DP load balance for the LLM text decoder backbone, the image and video feature-processing path in the visual encoder (ViT Encoder) also has an independent compute-load imbalance problem. This double imbalance across modules further aggravates the distributed-training bottleneck.
In summary, it is urgent to build a load-modeling system that matches the real compute characteristics of Transformers and multimodal models, together with a fine-grained adaptive data-assignment scheduler. This solves DP load imbalance at its root, reduces synchronization waiting overhead, and maximizes overall distributed-training efficiency and compute utilization.
2. Core optimization method: adaptive data redistribution based on accurate compute-cost modeling
The core logic for solving DP training load imbalance is clear: accurately quantify and model the real compute cost of individual samples and sample combinations, use measured compute-cost data as the central basis, and dynamically schedule training samples across DP nodes so that real compute load is equalized on all DP nodes. This completely eliminates synchronization-waiting loss caused by differences in compute progress between nodes.
In real engineering implementation, however, this optimization faces two key challenges that directly determine the practical effectiveness and usability of DP load balancing.
2.1. Key implementation challenges
First, it is difficult to guarantee the accuracy of compute-cost modeling. Overall training compute cost is composed of two module types with very different characteristics: the attention module has nonlinear quadratic complexity, while feed-forward networks and other basic modules are approximately linear. If the cost model cannot account for both nonlinear and linear compute characteristics, it cannot accurately fit the real compute cost of DP nodes under different combinations of long and short samples. Even if data samples are later rearranged, the expected load-balancing effect may not be achieved and additional load bias may even be introduced.
Second, the extra system overhead of data redistribution must be controlled. Sample rearrangement, packing-structure reconstruction, and cross-node data-exchange scheduling all introduce additional system and communication overhead. If the overhead of the optimization strategy itself is too high, it can directly offset the training-efficiency gain from load balancing or even drag down overall throughput. Therefore, the scheduler must be lightweight, intelligent, and low-overhead, keeping extra system cost within an acceptable range while preserving the load-balancing benefit.
2.2. LoongForge DP load-balancing design
For these two core challenges, Baidu Baige's all-modality training framework LoongForge provides a DP load-balancing solution tailored to the compute characteristics of Transformer architectures and multimodal models. Through adaptive data-rearrangement optimization, it performs fine-grained cross-DP sample redistribution within a single training iteration and achieves all-dimensional compute-load balancing.
The overall optimization process has two core stages. It is embedded throughout the native training process and requires no offline preprocessing.

2.2.1. Warm-up modeling: building an accurate compute-cost model
Through an online real-time performance-probing mechanism, LoongForge dynamically collects each DP node's real compute execution time, sample length, and other key features without disrupting normal training. Based on these data, it adaptively builds a DP-level cost-estimation model matching the model's compute characteristics. The process is fully automated and requires no manual parameter tuning or intervention.
The resulting model continuously adapts as the training environment and workload characteristics change. It has strong generality and can fit different model architectures, training configurations, and hardware platforms.
First, the compute load of a DP node is modeled in the following form:
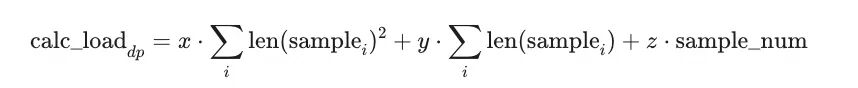
Here, the first term describes the quadratic complexity cost of attention; the second term describes the linear cost associated with linear layers and communication; the third term describes fixed kernel-launch overhead. The coefficients x, y, and z are to be solved. Their values are jointly determined by model architecture, training configuration, and hardware platform, and are estimated adaptively from online data during warm-up.
After n iterations in the warm-up stage, the following system of equations can be obtained:
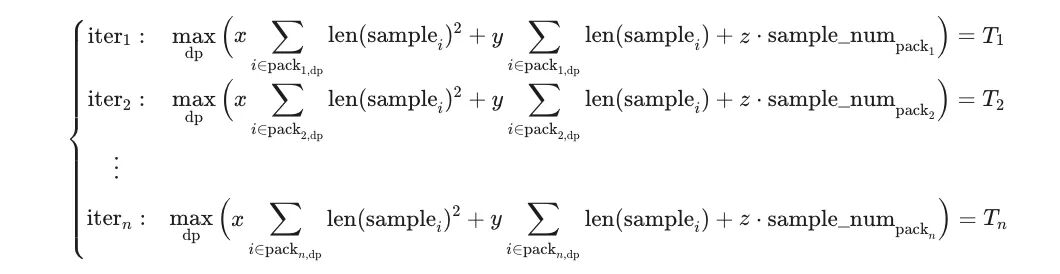
This modeling process attempts to infer the parameters x, y, and z of the sample load model from a set of iteration-level observations. Because the DP rank that triggers the max operation can change across iterations, the overall objective function forms a highly discontinuous piecewise structure in parameter space. Directly enumerating or analytically solving every possible max combination is computationally infeasible. For this reason, LoongForge introduces softmax as a differentiable approximation to max, transforms the problem into a continuous differentiable optimization form, and solves the model parameters numerically with least squares.
Specifically, the overall loss function is defined as:
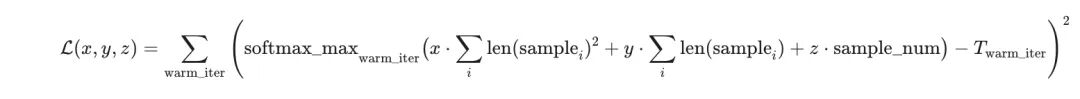
The goal is to solve for the optimal parameters under non-negative constraints:
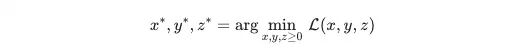
Based on this method, the optimal parameters can be solved iteratively. This process is triggered only once after the warm-up stage, so its impact on overall training efficiency is negligible.
2.2.2. Online adaptive redistribution: dynamically smoothing node load differences
After the optimal parameters are solved, LoongForge uses the compute-cost model trained in warm-up to evaluate in real time the compute pressure of pending samples on each DP node and dynamically perform adaptive cross-DP sample redistribution. The core optimization objective is to minimize the maximum total compute cost of any DP node in a single iteration, smoothing compute-time differences between nodes and greatly reducing global waiting overhead during gradient synchronization.
This method works out of the box. It fully supports mainstream multimodal models such as InternVL and Qwen2-VL/2.5-VL/3-VL, covers image and video multimodal training scenarios, and is compatible with dynamic-resolution model logic. It optimizes only native Data Parallelism and does not interfere with mainstream distributed strategies such as tensor parallelism or pipeline parallelism, so it can be directly adapted to existing training architectures. No changes to model training code are required: the capability is enabled with simple command-line arguments, and the automatic warm-up modeling flow requires no manual configuration or offline preprocessing.
The method has four core characteristics:
- It fits both the LLM text decoder and the ViT visual encoder, achieving dual multimodal load-balancing optimization.
- It supports continuous load tracking across microbatches, achieving iteration-level global load balancing rather than single-batch local optimization.
- It includes an intelligent redistribution trigger mechanism that automatically skips ineffective rearrangements and avoids wasted communication and scheduling resources.
- It uses an asynchronous pipeline design that fully hides data-rearrangement overhead, adding zero extra training latency.
2.3. Four core features
2.3.1. Dedicated load balancing for the ViT visual encoder
For the specific needs of multimodal model training, LoongForge extends beyond LLM text-decoder load balancing and designs a customized load-balancing solution for the ViT visual encoder. Compared with attention computation over text sequences, ViT processing of image and video pixel data has substantially different compute patterns and load characteristics, so it requires independent modeling and scheduling optimization.
This solution implements data redistribution and scheduling on both the input and output sides of the ViT encoder, ensuring that visual features are routed accurately to the corresponding DP nodes. This enables efficient alignment between visual features and LLM text embeddings and ultimately completes all-dimensional load balancing across both multimodal modules.
In addition, the load-balancing strategies for the ViT encoder and the LLM backbone are decoupled. They can be enabled independently or together, flexibly adapting to different training scenarios and performance-optimization needs.
2.3.2. Cross-microbatch load tracking: iteration-level global balance
When Gradient Accumulation is enabled, a full iteration consists of multiple microbatches executed sequentially and sharing one parameter update. In this setting, simple single-microbatch data redistribution only achieves local load balancing. It can still lead to accumulated load skew across microbatches and cannot reflect or optimize the real load distribution over a full iteration.
LoongForge therefore introduces cross-microbatch load tracking and scheduling. During gradient accumulation, each DP node's dedicated load tracker continuously records accumulated microbatch compute load, describes load trends over the full iteration from a global view, and uses that information for dynamic scheduling and redistribution. This upgrades the load-balancing target from single-microbatch local optimization to cross-microbatch full-cycle optimization, effectively eliminating load fluctuation and skew caused by gradient accumulation.
2.3.3. Dynamic intelligent triggering: avoiding wasted resources from ineffective rearrangement
The system does not need to perform data redistribution in every iteration. It has a built-in dual-condition intelligent trigger that precisely avoids resource loss from ineffective scheduling.
First is single-sample dominance detection: if the compute load of one sample already exceeds the average-load threshold of a DP node, redistribution cannot improve the overall load state, so the process is skipped automatically.
Second is imbalance-degree detection: data redistribution starts only when the proportional difference between the global maximum DP load and the average DP load exceeds a configured threshold. The system also automatically records the number of skipped and executed redistributions, making it easier for operations teams to monitor optimization effects and load state in real time.
2.3.4. Asynchronous rearrangement pipeline: hiding system overhead with zero extra training latency
To avoid system and communication loss from data redistribution at the root, LoongForge deploys data-rearrangement logic into the DataLoader's independent pin_memory worker thread and uses the Gloo backend's all_to_all communication operator for efficient cross-DP data exchange. This lets data rearrangement and GPU model computation run asynchronously in parallel.
The mechanism builds an efficient pipeline: while the training main thread performs forward and backward GPU computation for batch N, the independent pin_memory thread concurrently completes data rearrangement, sample reconstruction, and data preload preparation for batch N+1. As long as rearrangement scheduling takes less time than GPU model computation for the corresponding batch, the next batch's training data is ready in advance. All extra system overhead introduced by data rearrangement is completely hidden by the pipeline, and end-to-end training adds no extra latency.
3. Experimental validation: significant DP load-balancing gains in large-scale distributed training
Under fixed experimental conditions without All-Reduce communication overlap optimization, controlled experiments were conducted at different DP parallel scales.
Before enabling DP load balancing:
As the parallel scale expanded from DP32 to DP512, overall model-training throughput (TGS) continuously declined. The degradation was especially significant when scaling from DP256 to DP512, showing an accelerating downward trend. The core reason is that in large-scale distributed training, the larger number of DP nodes continuously amplifies compute-load imbalance introduced by the sample-length distribution. This creates a severe global waiting bottleneck during gradient synchronization and becomes a key factor limiting DP-scale expansion and causing major throughput degradation.
After enabling LoongForge DP load balancing:
The above performance-decay trend was significantly mitigated. Training throughput improved clearly at every DP scale, and the larger the scale, the more significant the optimization benefit: about 3.3% at DP256 and nearly 10% at the ultra-large DP512 scale.
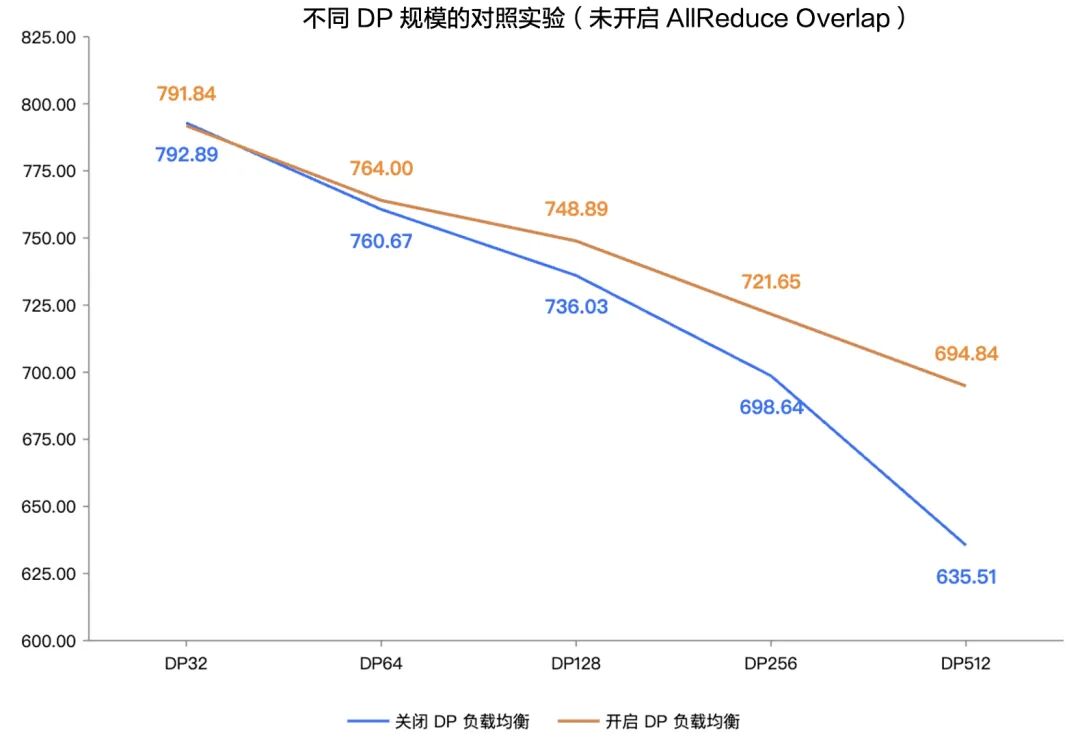
3.1. Experimental conclusion: effectively breaking the bottleneck of ultra-large-scale DP training
The results show that LoongForge's DP load balancing fundamentally alleviates load imbalance through fine-grained compute-load modeling and adaptive dynamic data redistribution. It significantly reduces invalid waiting time during gradient synchronization, improves distributed-training throughput and GPU resource utilization, and is especially suitable for ultra-large-scale cluster training scenarios.