LoongForge Multimodal Heterogeneous Parallel Training Acceleration: From Problems to Solutions
This article introduces LoongForge's heterogeneous parallel acceleration solution for multimodal large-model training, including three progressive strategies—heterogeneous TP, heterogeneous DP, and full separation parallelism—and deep integration with MoE A2A Overlap.
Official website: https://baidu-baige.github.io/LoongForge/
1. Background: the era of multimodal large models
1.1. From language to multimodality: the capability leap of large models
Since 2023, large models have entered a new stage of development, moving from pure language understanding toward multimodal perception and reasoning. The release of GPT-4V marked multimodal large language models (MLLMs) as a mainstream industry direction. Gemini, Claude 3, Qwen-VL, and many other models quickly followed, integrating understanding of images, video, audio, and other modalities into language models.
The force behind this trend is clear and strong: real-world information is inherently multimodal. A truly general-purpose agent must understand text, images, speech, and video at the same time, like humans do, before it can complete complex real-world tasks—from document understanding, UI operation, and robot control to scientific research assistance.
1.2. Mainstream architecture: the Encoder-Projector-Decoder paradigm
After broad exploration by the community, current multimodal large models have converged on a relatively unified architecture paradigm:
Typical multimodal large-model architecture
Image / Video
↓
[Vision Encoder (ViT)]
↓
[Projector]
├──→ [LLM Decoder] → Output
↑
Text tokens- Vision Encoder: usually a ViT (Vision Transformer) architecture, responsible for encoding images or video frames into visual token sequences. Mainstream designs range from 0.3B to 6B parameters, such as the 0.6B ViT used by Qwen3-VL and the 6B InternViT used by InternVL 2.5.
- Projector: a lightweight modality-alignment layer, usually an MLP or Cross-Attention, that maps visual tokens into the representation space of the language model.
- LLM Decoder: the large-language-model backbone, responsible for fusing multimodal information and generating the final output. Its parameter count ranges from 7B to 235B, making it the dominant part of the model.
1.3. The encoder-decoder scale gap keeps growing, and MoE architectures are becoming common
The parameter scale of multimodal large models is rising quickly, while the ViT part remains basically unchanged:
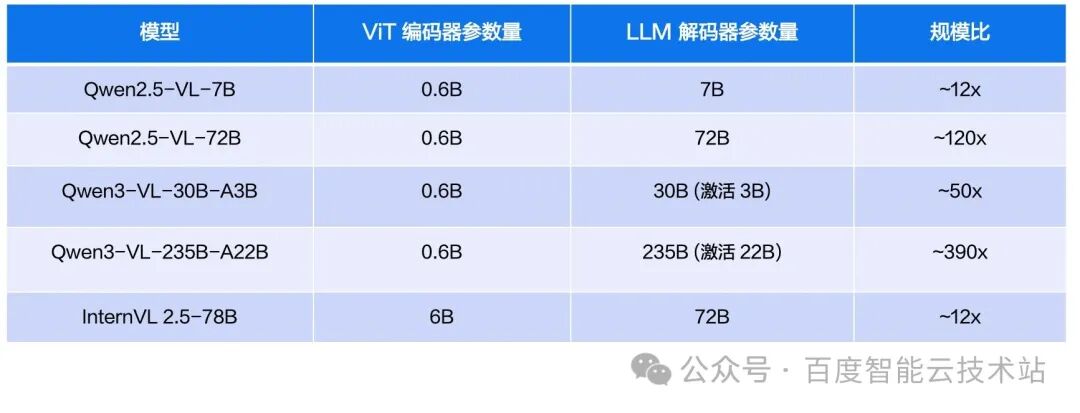
Two notable trends deserve attention:
- Trend 1: decoder size grows rapidly while encoder size stays relatively stable. ViT encoder parameter counts have long remained around 0.3B to 6B, while LLM decoders have grown from the original 7B to 72B and even 235B. The scale gap has expanded from roughly 10x to roughly 100x and even 400x.
- Trend 2: MoE architectures are becoming the mainstream choice for large-scale multimodal models. The Qwen3-VL series fully shifts to MoE architectures (30B-A3B and 235B-A22B), greatly expanding model capacity while maintaining inference efficiency. But MoE introduces Expert Parallelism and All-to-All communication during training, further increasing training-system complexity.
2. Limitations of the current training paradigm
The decoder is much larger than the encoder, usually by one to two orders of magnitude. In distributed training, this scale difference causes a series of efficiency problems, while the system must also account for characteristics of mainstream MoE models.
Problem 1: unified TP causes encoder communication waste
The traditional approach uses a unified Tensor Parallel (TP) configuration for the entire model. For example, to satisfy memory requirements for a 72B decoder, TP=4 or even TP=8 may be needed. But for a 0.6B ViT encoder, TP=4 leaves only 150M encoder parameters on each card. The compute amount is extremely small, while the AllReduce communication overhead introduced by TP occupies an overwhelming share of time. The encoder becomes communication-bound rather than compute-bound.
Traditional solution (unified TP=4):
GPU0: ViT_shard_0 → AllReduce → LLM_shard_0
GPU1: ViT_shard_1 → AllReduce → LLM_shard_1
GPU2: ViT_shard_2 → AllReduce → LLM_shard_2
GPU3: ViT_shard_3 → AllReduce → LLM_shard_3
↑
Encoder TP communication becomes the bottleneck
(compute is too small and communication share is too high)Problem 2: PP pipeline bubbles
In Pipeline Parallelism (PP), the encoder usually exists only in the first pipeline stage. This means that when decoder layers are evenly divided, the first pipeline stage has more parameters and compute than the other stages, causing pipeline bubbles.
Solving this usually requires manually configuring the number of decoder layers in the first pipeline stage to reach compute balance. But because the encoder's compute characteristics are very different from the decoder's, manual configuration is cumbersome and difficult, and can still lead to imbalanced pipeline computation across stages.
Traditional solution (PP=4, encoder in stage 0):
Stage 0: [ViT Forward] [LLM layers 0-7 fwd] ... [bwd] ...
Stage 1: [ IDLE ] [LLM layers 8-15 fwd] ... [bwd] ...
Stage 2: [ IDLE ] [ wait ] [layers 16-23 fwd] ... [bwd] ...
Stage 3: [ IDLE ] [ wait ] [ wait ] [layers 24-31 fwd] ...
↑
Stage 1/2/3 are completely idle during encodingProblem 3: MoE communication stacks on top
When the decoder uses a Mixture-of-Experts (MoE) architecture, such as Qwen3-VL-30B-A3B with top-8 routing, All-to-All communication introduced by Expert Parallelism (EP) becomes another significant bottleneck. In the traditional solution, encoder inefficiency stacks with MoE communication overhead and worsens overall training efficiency. This requires encoder optimization and decoder optimization to be enabled together so that end-to-end efficiency improves.
An ideal multimodal-training parallel solution should satisfy the following:
- Use the optimal parallel strategy for the encoder: eliminate unnecessary TP communication overhead.
- Fully utilize all GPU compute: eliminate GPU idleness during the encoding phase.
- Be orthogonal to MoE optimization: allow A2A overlap communication-hiding benefits to be used at the same time.
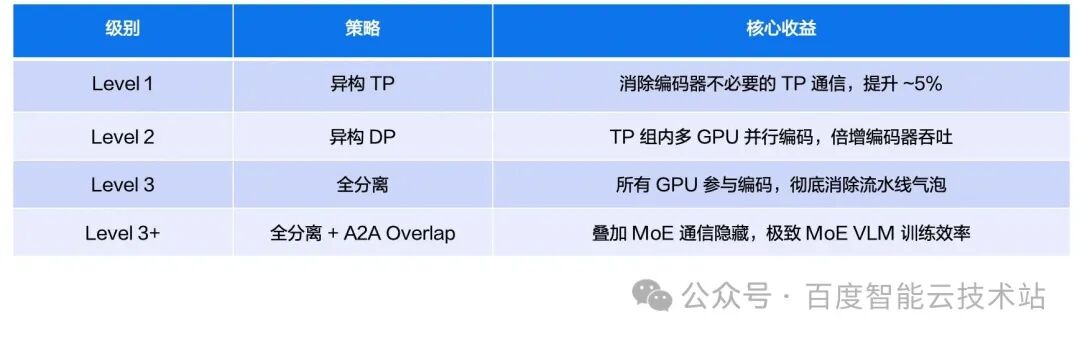
3. Solution design: three progressive levels of heterogeneous parallelism
LoongForge designs a three-level progressive heterogeneous parallel solution. Each level further expands the encoder's effective data parallelism on top of the previous level, gradually maximizing multimodal training efficiency. The solution refers to Kimi's separated-parallelism design (https://arxiv.org/abs/2602.02276).
3.1. Level 1: Heterogeneous Tensor Parallelism
Design idea
The most direct optimization is: since the encoder does not need such a large TP degree, let the encoder and decoder use different TP sizes.
LoongForge's heterogeneous TP treats the model as multiple independent submodules, such as encoder and decoder. Each submodule can configure an independent TP process group, and the system automatically switches parallel context at module execution boundaries.
Implementation mechanism
The core implementation is based on a parallel-state snapshot and switching mechanism:
- State storage:
_ParallelStatesDictstores independent parallel states for each submodule (text_decoder,image_encoder,video_encoder,audio_encoder), including TP group, DP group, PP group, and all othermpu-level variables. - Process-group creation:
create_parallel_state(module_name, tp_size)creates a completely new set of process groups for the encoder according to the specified TP size. For example, when decoder TP=4 and encoder TP=2, four GPUs are divided into two encoder TP groups. - Automatic switching: PyTorch forward/backward hooks call
change_parallel_state("image_encoder")before encoder execution to switch to the encoder parallel context, and callchange_parallel_state("text_decoder")afterward to switch back to the decoder.
# Pseudo-code: parallel-state switching (simplified)
class OmniEncoderModel:
def _pre_forward_hook(self, module, input):
change_parallel_state("image_encoder") # switch to encoder TP group
def _post_forward_hook(self, module, input, output):
change_parallel_state("text_decoder") # switch back to decoder TP groupUsage
Only the encoder TP size needs to be specified in the YAML configuration:
# configs/models/image_encoder/qwen3_vit.yaml
_target_: loongforge.models.encoder.Qwen3VisionModelConfig
num_layers: 27
hidden_size: 1152
# ... other config ...
tensor_model_parallel_size: 2 # encoder TP=2 (decoder TP is controlled by CLI args)Performance
Using Qwen3-VL as the baseline model at 32k sequence length in a 4-machine A-card environment, enabling heterogeneous TP gives throughput of about 800 tokens/second, which is used as the base.
3.2. Level 2: Heterogeneous Data Parallelism
Design idea
Heterogeneous TP solves the encoder communication-waste problem, but it does not fully utilize compute. When encoder TP=1 and decoder TP=4, each of the four GPUs in a TP group holds a complete encoder replica, but only one GPU runs the encoder; the encoder replicas on the other three GPUs are idle during forward.
The core insight of heterogeneous DP is: since every GPU has a complete encoder, let them process different data simultaneously.
Implementation mechanism
When heterogeneous DP is enabled, each GPU inside a TP group independently processes a different microbatch during the encoding phase:
Heterogeneous DP (decoder TP=4, encoder TP=1):
┌─── TP Group ────────────────────────────────┐
│ GPU0: ViT(batch_0) → embed_0 │
│ GPU1: ViT(batch_1) → embed_1 │ encoding: 4-way parallel
│ GPU2: ViT(batch_2) → embed_2 │
│ GPU3: ViT(batch_3) → embed_3 │
│ │
│ broadcast embed_i → all GPUs │ embedding distribution
│ │
│ GPU0-3: standard TP=4 decoder fwd/bwd │ decoding: normal TP
└──────────────────────────────────────────────┘Key implementation points:
- Independent encoding: each TP rank uses its
inner_group_idto fetch the corresponding microbatch frombatch_listand independently run encoder forward. - Embedding broadcast: after encoding, each rank broadcasts its embedding to all other ranks in the TP group through
hetero_dp_get_tensor, because decoder TP requires all ranks to have the same input. - Gradient return: during decoder backward, a registered gradient hook (
vit_grad_hook_factory) captures the gradient flowing back to the embedding and triggers encoder backward only on the corresponding owner rank.
# Pseudo-code: heterogeneous DP forward logic (simplified)
def forward(self, batch_list, forward_group_id, inner_group_id):
# Each rank processes its corresponding batch
my_batch = batch_list[forward_group_id * tp_size + inner_group_id]
# Run encoder independently
embedding = self.encoder(my_batch)
# Store in context for later broadcast
self.vit_contexts[forward_group_id] = embedding
# Decoding phase: broadcast embedding from each corresponding rank
for i in range(tp_size):
emb_i = hetero_dp_get_tensor(self.vit_contexts, src=i)
# concatenate into decoder inputUsage
MODEL_PARALLEL_ARGS=(
--tensor-model-parallel-size 4
--pipeline-model-parallel-size 2
--enable-encoder-hetero-dp # one argument enables it
)The encoder YAML must set tensor_model_parallel_size: 1.
Performance
Using Qwen3-VL as the baseline at 32k sequence length in a 4-machine A-card environment, heterogeneous DP reaches about 855 tokens/second, about 6.8% faster than the base.
3.3. Level 3: Full Heterogeneous DP
Design idea
Heterogeneous DP raises the encoder's effective DP degree to TP size, usually 4 to 8, but it is still limited to the TP dimension. When PP is used, GPUs in non-first stages remain idle during encoding.
The core idea of full separation parallelism is: expand the encoder's data parallelism to the entire model-parallel group (TP × PP × CP), so all GPUs participate in visual encoding during the encoding phase. For a complete iteration, full separation first uses all cards to compute encoder results for all microbatches. The encoder no longer runs only on PP stage 0; all stages have an Encoder and can perform encoder computation simultaneously. After computation, intermediate results are stored, then the full decoder execution runs and uses the stored intermediate results as decoder input. This completely separates encoder and decoder computation.
This means the encoding phase and decoding phase are fully decoupled and separated in time, rather than interleaving encoder and decoder execution as in traditional training. This is why it is called “full separation.”
Implementation mechanism
Full separation parallelism splits one training iteration into three explicit phases:
Full separation parallelism (TP=4, PP=2, model-parallel group size=8):
════════ Phase 1: Encoding (all GPUs independently encode) ═══════════
│ Stage0-GPU0: ViT(batch_0) Stage0-GPU1: ViT(batch_1) │
│ Stage0-GPU2: ViT(batch_2) Stage0-GPU3: ViT(batch_3) │
│ Stage1-GPU4: ViT(batch_4) Stage1-GPU5: ViT(batch_5) │ encoder DP=8
│ Stage1-GPU6: ViT(batch_6) Stage1-GPU7: ViT(batch_7) │
│ → gather_variable_shape_embeddings() → rank 0 │ gather all embeddings
════════ Phase 2: Decoding (standard PP+TP pipeline) ═════════════
│ Stage 0 (TP=4): LLM layers 0-15 [1F1B schedule] │
│ Stage 1 (TP=4): LLM layers 16-31 [1F1B schedule] │ normal pipeline
│ PreProcessNode: rank0 broadcast embedding → all ranks │ distribute embeddings on demand
════════ Phase 3: Encoder backward (gradients return to GPUs) ═══════════
│ scatter_variable_shape_embeddings(grads) → GPUs │ scatter gradients
│ GPUs: torch.autograd.backward(local_embedding) │ independent encoder backward
│ DDP bucket sync for encoder params │ encoder gradient sync
════════════════════════════════════════════════════════════Key implementation details:
Gather/Scatter for variable-length embeddings
Because different samples contain different numbers of image tokens, especially with highly variable videos, encoder-output tensor shapes are inconsistent across GPUs. LoongForge implements two communication primitives, gather_variable_shape_embeddings and scatter_variable_shape_embeddings, to support collection and distribution of variable-length tensors across ranks:
# Exchange shape information first, then gather variable-length tensors as needed
def gather_variable_shape_embeddings(embedding, model_parallel_group):
# 1. all_gather shapes
local_shape = torch.tensor(embedding.shape)
all_shapes = all_gather(local_shape, group=model_parallel_group)
# 2. pad to max shape, then all_gather data
max_shape = max(all_shapes)
padded = pad_to(embedding, max_shape)
all_embeddings = all_gather(padded, group=model_parallel_group)
# 3. unpad and return list
return [unpad(emb, shape) for emb, shape in zip(all_embeddings, all_shapes)]Delayed encoder backward
In traditional interleaved forward-backward execution, encoder backward is triggered immediately when the first decoder microbatch runs backward. In full separation mode, encoder backward must wait until all decoder microbatches finish forward-backward and then run uniformly. The system uses full_hetero_dp_grad_hook_factory to capture gradients and temporarily store them in grad_list, then returns them uniformly in Phase 3.
Instantiate the encoder only in the first VPP chunk
To avoid repeated encoder instantiation on every PP stage and wasting memory, full separation creates the encoder only on the first Virtual Pipeline Parallel chunk:
# omni_model_provider.py
if enable_full_hetero_dp:
add_encoder = (vp_stage == 0) # only the first VPP chunk
else:
add_encoder = (pp_stage == 0) # only the first PP stageMock microbatch padding
When the actual number of microbatches is not divisible by the model-parallel group size, the system automatically pads empty mock microbatches to keep gather/scatter operations aligned.
Full-separation intermediate-result offload
When full separation is enabled, the encoder and decoder run independently. To ensure each decoder microbatch can obtain its corresponding visual features, the system must compute encoder results for all data in the entire GBS (Global Batch Size) before decoder forward and temporarily store the results in GPU memory. When input sequence length is large or GBS is high, these intermediate results, including visual embedding, visual_pos_masks, and deepstack_visual_embeds, can occupy a large amount of memory and may cause OOM during the decoder phase.
To solve this, full separation supports encoder-result offload. After encoder forward finishes, intermediate results are asynchronously moved to CPU memory. When each decoder microbatch actually needs them, they are loaded back to GPU on demand. In this way, with a small cost in CPU memory and H2D transfer overhead, peak GPU memory usage is significantly reduced, supporting longer sequences or larger batches.
Usage
MODEL_PARALLEL_ARGS=(
--tensor-model-parallel-size 4
--pipeline-model-parallel-size 2
--enable-full-hetero-dp # enable full separation
--full-hetero-dp-cpu-offload # enable full-separation intermediate offload
--use-distributed-optimizer
)Performance
Using Qwen3-VL as the baseline model at 32k sequence length in a 4-machine A-card environment, full separation parallelism reaches about 900 tokens/second, about 12.5% faster than the base.
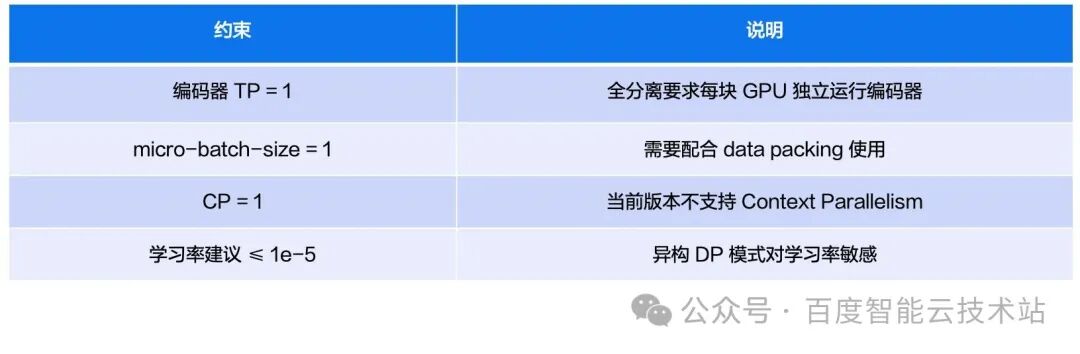
Constraints
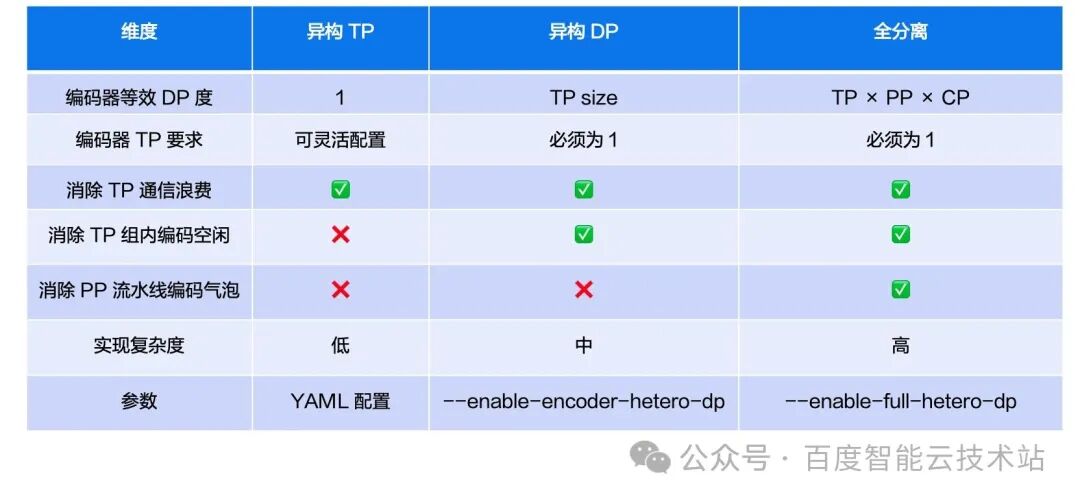
3.4. Comparison of the three-level solution
4. Deep integration: full separation + MoE A2A Overlap
4.1. Communication bottleneck in MoE training
For MoE-architecture multimodal models such as Qwen3-VL-30B-A3B, Expert Parallelism (EP) introduces a large amount of All-to-All communication. In each Transformer layer, the MoE operation involves two All-to-All operations:
Token Dispatch (A2A) → Expert Computation → Token Combine (A2A)
↑ ↑
tokens are dispatched to ranks with experts expert outputs are collected back to original ranksWhen EP=8, the communication volume of two A2A operations per layer is proportional to sequence length and expert hidden size, becoming a significant bottleneck in long-sequence training.
4.2. Principle of 1F1B A2A Overlap
LoongForge's A2A Overlap solution borrows from the idea of DeepSeek-V3 DualPipe. It decomposes a Transformer layer into fine-grained sub-operation nodes and interleaves scheduling across different microbatches:
Fine-grained node decomposition:
TransformerLayer = [Attn] → [PostAttn/Router] → [Dispatch A2A] → [Experts] → [Combine A2A] → [PostCombine]
compute compute comm compute comm compute
Cross-microbatch interleaved scheduling:
MB0: [Attn] [PostAttn] [Dispatch─A2A] [Experts] [Combine─A2A] [PostCombine]
MB1: [Attn─────────] [PostAttn] [Dispatch─A2A] [Experts] ...
↑ ↑
MB1 compute hides MB0 A2A communicationIn implementation, each sub-operation is encapsulated as a ScheduleNode and assigned to a compute stream or communication stream. The 1F1B scheduler automatically interleaves execution.
4.3. Fusion challenge and solution
Integrating full separation parallelism with A2A Overlap faces a key challenge: the fine-grained A2A Overlap scheduler needs to obtain encoder outputs through PreProcessNode, but in full separation mode encoder outputs are precomputed in Phase 1 of train_step rather than computed in real time inside PreProcessNode.
The two execution modes must be made compatible by design.
LoongForge's solution is to pass the full heterogeneous-DP context into the fine-grained scheduler:
# PreProcessNode extension (supports full separation mode)
class PreProcessNode:
def __init__(self, ..., enable_full_hetero_dp=False,
enable_encoder_hetero_dp=False,
batch_list=None, forward_group_id=None, inner_group_id=None):
self.enable_full_hetero_dp = enable_full_hetero_dp
# ... cache context ...
def forward_impl(self, ...):
if self.enable_full_hetero_dp:
# obtain precomputed embedding from embedding_list
embedding = retrieve_precomputed_embedding(forward_group_id, inner_group_id)
# broadcast to all TP ranks
hetero_dp_get_tensor(embedding, src=0)
# register gradient hook for Phase 3 backward
register_grad_hook(embedding, grad_list)
elif self.enable_encoder_hetero_dp:
# independent encoding inside TP group + broadcast
embedding = run_encoder_independently(batch_list, inner_group_id)
hetero_dp_get_tensor(embedding)
else:
# standard path: directly run encoder
embedding = self.encoder(input)
return embeddingWith this design, TransformerModelChunkSchedulePlan carries all heterogeneous-DP context correctly when constructing the schedule plan, allowing A2A Overlap microbatch interleaving to work seamlessly with precomputed embeddings from full separation mode.
4.4. Fine-Grained Activation Offload
A2A Overlap depends on block-level interleaved execution and is incompatible with traditional full-layer recomputation. To save memory, LoongForge provides module-level selective recomputation + fine-grained activation offload:
- Selective recomputation: only recompute modules involved in A2A overlap, namely
attn,post_attn, andmlp, while preserving the scheduling structure. - Tensor-level offload: asynchronously move intermediate activations such as
dispatched_inputandpre_mlp_layernorm_outputto CPU and asynchronously load them back to GPU when needed.
--recompute-granularity selective \
--recompute-modules a2a_overlap_attn a2a_overlap_post_attn a2a_overlap_mlp \
--fine-grained-activation-offloading \
--offload-tensors dispatched_input pre_mlp_layernorm_outputThis approximates the memory savings of full-layer recomputation without sacrificing A2A overlap effectiveness.
5. Feature compatibility
5.1. Training-phase compatibility

The two training phases use the same model architecture and forward logic and are registered uniformly through @register_model_trainer(family, training_phase). The heterogeneous-parallel implementation is completely transparent to the training phase.
5.2. Encoder Freeze compatibility
In SFT scenarios, freezing the visual encoder is common: it preserves pretrained visual-understanding capability and trains only the decoder's multimodal-alignment capability. LoongForge supports configuration-level freeze:
# Hydra override style
+model.image_encoder.freeze=TrueIn heterogeneous DP and full separation modes, encoder-freeze behavior is fully correct:
- Encoder forward still runs normally to provide embeddings to the decoder.
- Encoder parameters have
requires_grad=Falseand do not run backward. - In full separation mode, Phase 3 encoder backward is skipped automatically.
- Encoder parameters do not participate in distributed-optimizer gather/reduce.
5.3. ViT DP Load Balancing compatibility
Different samples contain different numbers of images or video frames, causing encoder compute imbalance across DP ranks. LoongForge's use-vit-dp-balance feature rearranges samples during data loading to balance encoder compute across ranks. This feature runs correctly after switching to the encoder parallel context and is fully compatible with heterogeneous parallelism.
5.4. Full compatibility matrix
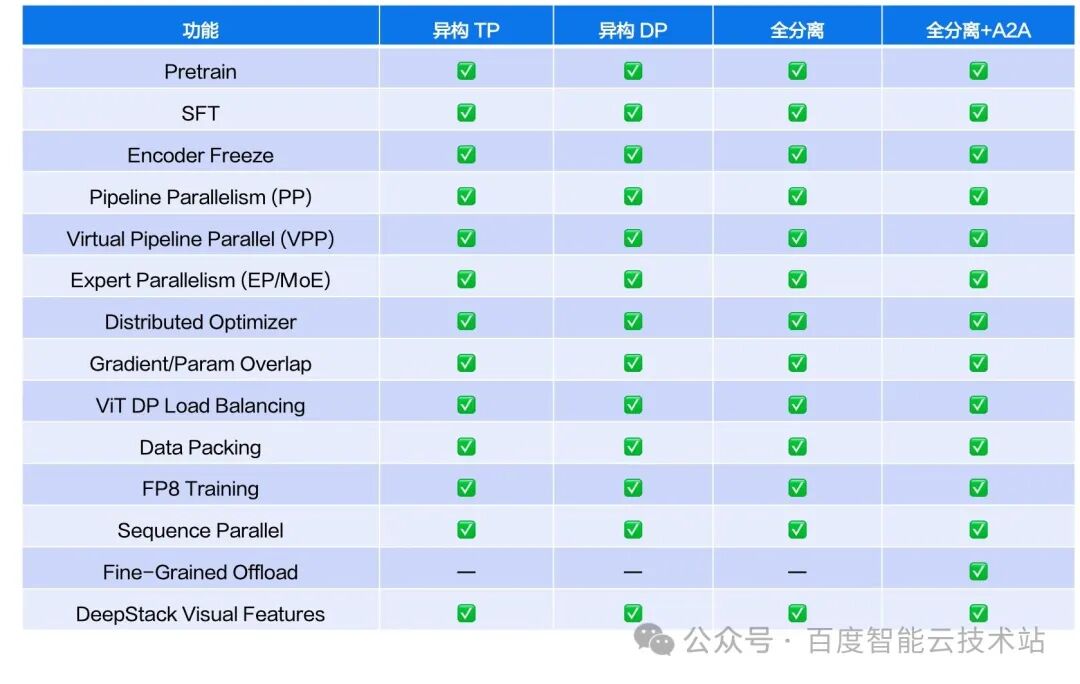
6. Quick start
Heterogeneous TP, heterogeneous DP, and full separation can run by configuring the corresponding LoongForge training arguments. --enable-encoder-hetero-dp enables heterogeneous DP, and --enable-full-hetero-dp enables full separation. When heterogeneous DP or full separation is enabled, TP=1 must be specified in YAML.
6.1. Heterogeneous TP
Specifying the ViT tp size in YAML enables heterogeneous TP by default.
_target_: loongforge.models.encoder.Qwen2VisionRMSNormConfig
num_layers: 32
hidden_size: 1280
kv_channels: 80
ffn_hidden_size: 3420
patch_size: 14
num_attention_heads: 16
num_query_groups: 16
image_size: [1344, 1344]
activation_func: ${act:silu}
add_bias_linear: true
add_qkv_bias: true
swiglu: true
gated_linear_unit: true
position_embedding_type: "none"
bias_activation_fusion: False
hidden_dropout: 0
attention_dropout: 0
normalization: "RMSNorm"
apply_rope_fusion: true
tensor_model_parallel_size: 1
recompute_granularity: full
recompute_method: uniform
recompute_num_layers: 1
model_type: "qwen2_5_vit"6.2. Heterogeneous DP
#!/bin/bash
# Qwen2.5-VL-7B SFT with Heterogeneous DP
LOONGFORGE_PATH=/path/to/LoongForge
MEGATRON_PATH=$LOONGFORGE_PATH/third_party/Loong-Megatron
MODEL_PARALLEL_ARGS=(
--attention-backend flash
--tensor-model-parallel-size 4
--pipeline-model-parallel-size 1
--use-distributed-optimizer
--enable-encoder-hetero-dp
)
PYTHONPATH=$MEGATRON_PATH:$LOONGFORGE_PATH:$PYTHONPATH \
torchrun --nproc_per_node 8 --nnodes 1 \
$LOONGFORGE_PATH/loongforge/train.py \
--model-name qwen2_5_vl_7b \
--training-phase sft \
"${MODEL_PARALLEL_ARGS[@]}" \
+model.image_encoder.freeze=True \
--micro-batch-size 1 \
--global-batch-size 32 \
--lr 1e-5 \
# ... other training args6.3. Full separation parallelism for encoder and decoder
#!/bin/bash
# Qwen3-VL-30B-A3B SFT with Full Separation + A2A Overlap
MODEL_PARALLEL_ARGS=(
--attention-backend flash
--tensor-model-parallel-size 1
--pipeline-model-parallel-size 2
--expert-model-parallel-size 4
--moe-token-dispatcher-type alltoall
--num-virtual-stages-per-pipeline-rank 2
--use-distributed-optimizer
--enable-full-hetero-dp
--overlap-moe-expert-parallel-comm
--delay-wgrad-compute
)
# Optimize A2A overlap
export CUDA_DEVICE_MAX_CONNECTIONS=32
PYTHONPATH=$MEGATRON_PATH:$LOONGFORGE_PATH:$PYTHONPATH \
torchrun --nproc_per_node 8 --nnodes 4 \
$LOONGFORGE_PATH/loongforge/train.py \
--model-name qwen3_vl_30b_a3b \
--training-phase sft \
"${MODEL_PARALLEL_ARGS[@]}" \
+model.image_encoder.freeze=True \
--micro-batch-size 1 \
--global-batch-size 64 \
--lr 1e-5 \
--recompute-granularity selective \
--recompute-modules a2a_overlap_attn a2a_overlap_post_attn a2a_overlap_mlp \
--fine-grained-activation-offloading \
--offload-tensors dispatched_input pre_mlm_layernorm_output \
# ... other training args7. Summary
LoongForge's heterogeneous parallel solution systematically solves the compute-heterogeneity challenge between encoder and decoder in multimodal large-model training. Through three progressive levels, it gradually releases training efficiency:
The design follows these principles:
- Progressive optimization: the three-level solution can be selected flexibly according to model size and cluster configuration, without requiring an all-at-once switch.
- Minimal intrusion: implemented through hooks, parallel-state switching, fine-grained scheduling nodes, and related mechanisms, with no intrusion into model code.
- Configuration-driven: users only need to add one or two CLI arguments to enable it, without modifying training-script logic.
- Broad compatibility: fully compatible with pretrain, SFT, encoder freeze, LoRA, PP, EP, distributed optimizer, and more.
For next-generation multimodal large models using MoE architectures, such as Qwen3-VL-235B-A22B, the combination of full separation + A2A Overlap provides the current best end-to-end training-efficiency solution.