Training Cycle Halved: LoongForge End-to-End Optimization for GR00T N1.6 Delivers 2.3× Throughput
To address IO stalls, communication overhead, and inefficient operator scheduling in GR00T N1.6 VLA model training, Baidu Baige's LoongForge delivers end-to-end system-level optimization, achieving up to 2.3× training throughput and shortening the overall training cycle by 56.6%.
Official website: https://baidu-baige.github.io/LoongForge/
1. Background: the capability leap and challenges of GR00T N1.6 as an embodied-intelligence foundation
As humanoid robots accelerate toward industrialization, Vision-Language-Action (VLA) models have become a core technical path for embodied intelligence, thanks to their ability to connect perception, understanding, and action end-to-end. Among the embodied-intelligence foundation models, NVIDIA's open-source GR00T N series stands out as a representative core technology stack for humanoid-robot scenarios and is widely used in robotic intelligence training and R&D deployment.
Released in 2025, GR00T N1.6 further revamps both the model architecture and the action-generation paradigm, significantly strengthening end-to-end intelligent control of humanoid robots. The model uses Cosmos-Reason-2B as its multimodal vision-language perception core, and introduces a 32-layer DiT backbone for action generation, jointly modeling first-person robot video, proprioceptive state, and natural-language instructions as a shared policy representation—unifying perception, understanding, and action control.
The deep DiT enables high-precision modeling of long action sequences and substantially improves intelligent-control quality, but it also turns model training into a workload that is both compute- and communication-intensive, with high training cost and difficulty.
According to the official configuration, the pre-training stage uses a global batch size of 16,384 and runs roughly 300K steps on 1,024 H100 GPUs. Even fine-tuning on a downstream task on a single node takes several days. Data IO stalls, multi-GPU communication overhead, and inefficient training scheduling all combine to make GR00T N1.6 training expensive and slow, hindering rapid model iteration.
2. Solution overview: LoongForge end-to-end system-level optimization
To further improve GR00T N1.6 training efficiency, the Baidu Baige team applied system-level optimization and deep refactoring across the full training pipeline, on top of the in-house, open-source full-modal training framework LoongForge.
Targeting the characteristics of VLA training, LoongForge focuses on three directions: data IO pipeline, communication-computation overlap, and training scheduling:
- Introduce asynchronous prefetch in data processing to mitigate GPU idling caused by data loading and transfer latency;
- Use a distributed optimizer with fine-grained communication-computation overlap to reduce extra cost from multi-GPU synchronization stalls;
- Adapt CUDA Graph to cut launch overhead from the large number of small-granularity operators.
Compared to the official training implementation, LoongForge ultimately delivers up to 2.3× training throughput and reduces the overall training cycle by 56.6%. So how exactly does LoongForge release more GPU compute and accelerate GR00T N1.6 training? Below we systematically break down the key ideas and technical implementation.
3. Inside the 2.3× speedup: three engineering optimizations
To unlock GR00T N1.6's training potential, we did not stop at simple parameter tuning, but performed system-level optimization at three layers: data IO pipeline, communication-computation overlap, and training scheduling.
Optimization 1: IO pipeline — asynchronous data prefetch
GR00T N1.6 data preprocessing involves CPU-heavy operations such as video decoding, image augmentation, and multimodal encoding. In the Lerobot framework, the GPU spends a large fraction of time waiting on data—a classic IO stall.
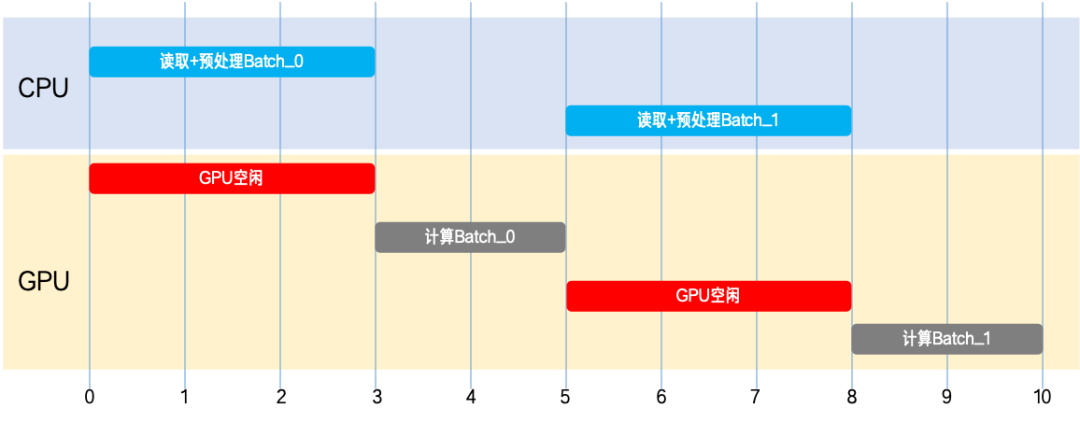
LoongForge decouples data production from GPU training via a three-level asynchronous pipeline:
- Level 1 — data reading: multiple DataLoader workers read from disk in parallel, each prefetching n additional batches.
- Level 2 — CPU preprocessing: a dedicated daemon thread runs image / video / text preprocessing, decoupled from the training main loop via double-buffered queues to avoid cross-process tensor serialization overhead.
- Level 3 — GPU DMA transfer: with pinned memory and non-blocking transfers, the GPU asynchronously moves data into VRAM on a dedicated copy stream, fully overlapping with computation.
While the GPU computes the current batch, the next batch is being transferred, the one after is being preprocessed, and an even later batch is being read—forming a complete pipeline overlap.

With this IO-pipeline optimization, GPU data-wait time is dramatically compressed and IO stalls are largely hidden.
Optimization 2: communication-computation overlap — fine-grained overlap driven by the Megatron Distributed Optimizer
When training GR00T N1.6 in the Lerobot framework, the following bottlenecks are typical:
- No parameter prefetch: forward must wait for the current layer to finish before fetching the next layer's parameters, so communication cannot start early.
- Scattered gradient storage with delayed sync: per-layer gradients are stored independently, so async communication cannot be triggered bucket-by-bucket. AllReduce only fires after backward completes, serializing sync with computation.
To resolve these bottlenecks, LoongForge integrates the Megatron Distributed Optimizer. Through contiguous gradient buffers and hook-based communication scheduling, parameter sync, gradient reduction, and model computation are deeply interleaved, achieving fine-grained communication-computation overlap, hiding communication overhead, and lifting training throughput.
Comparison of baseline vs. LoongForge core optimization features:
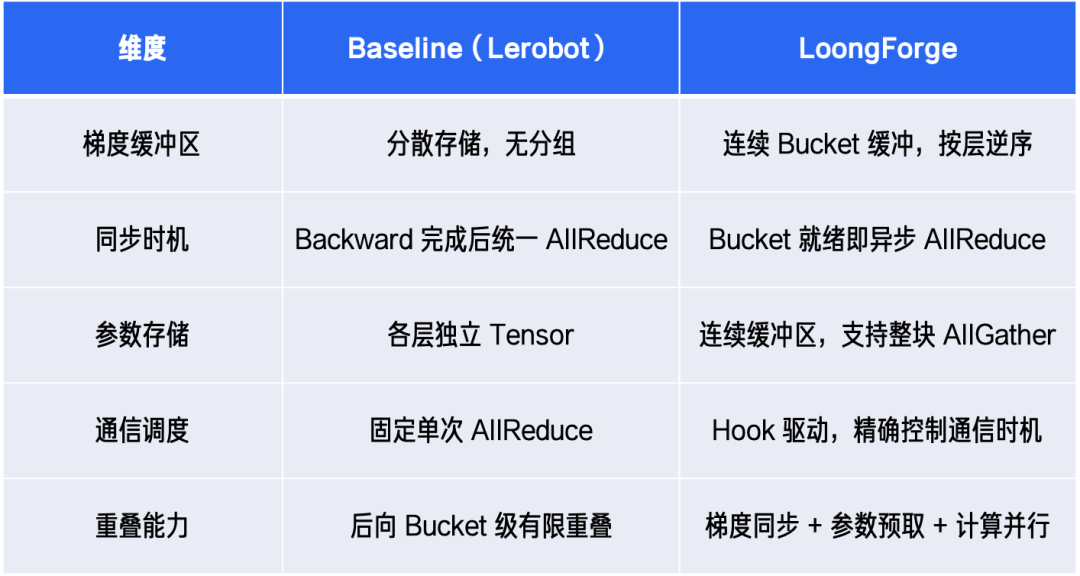
Specific measures include:
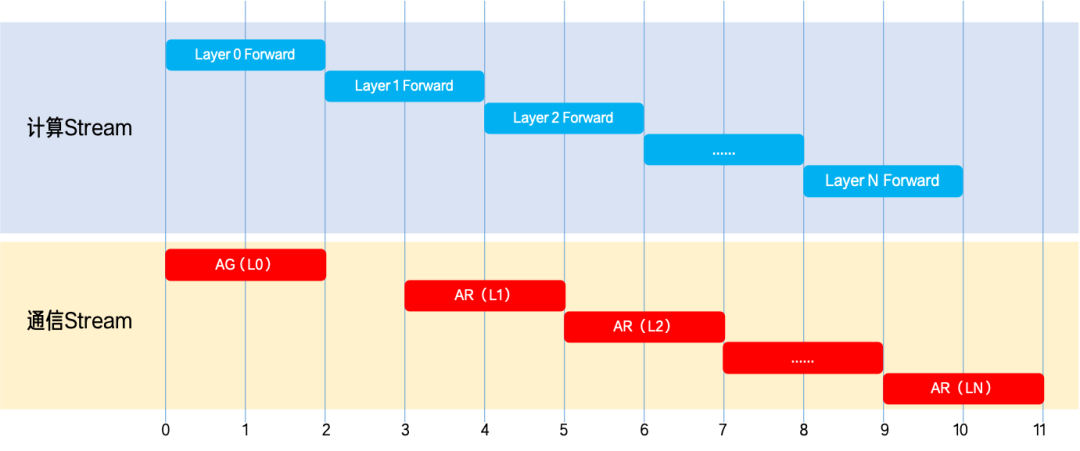
- Per-layer parameter prefetch in forward: during forward, a pre-hook issues an AllGather for the next layer's parameters on a dedicated NCCL communication stream, parallelizing communication with the current layer's computation. The total time goes from "Forward + Backward + Communication + Step" to "Forward + max(Backward, Communication) + Step", so communication overhead is almost fully hidden.
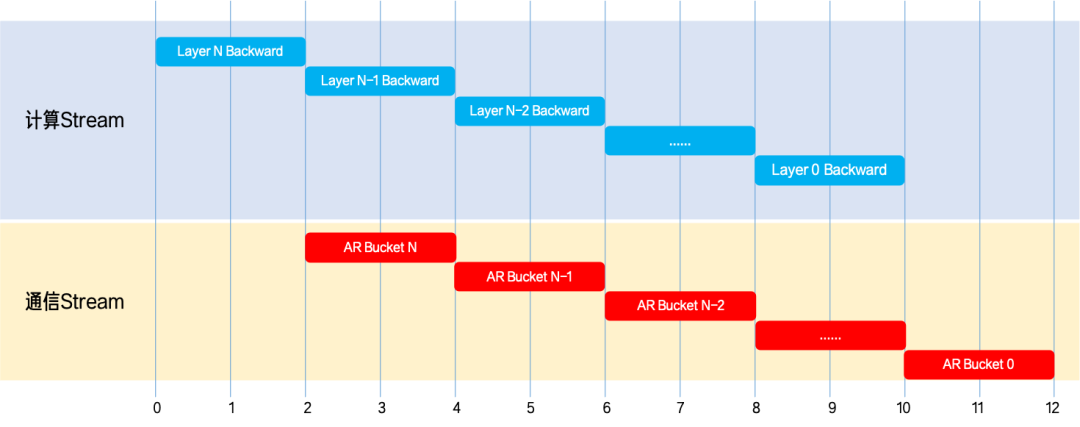
- Bucket-based gradient sync overlap: contiguous gradient buffers are arranged in reverse-backward order. As soon as a bucket finishes, AllReduce is launched on a dedicated NCCL stream, so computation and communication run in parallel. On the timeline, the compute stream and the NCCL communication stream are highly concurrent.
Optimization 3: training-scheduling optimization — Per-Microbatch CUDA Graph for GR00T N1.6
Python scheduling and GPU kernel launch overhead are often invisible bottlenecks in large-model training. In VLA training such as GR00T N1.6, where forward, backward, and loss compute trigger a large number of tiny kernels, eager-mode launching keeps amplifying CPU overhead and prevents the GPU from being fully utilized.
CUDA Graph is a widely used optimization in the GPU ecosystem that uses graph replay to cut Python scheduling and kernel launch overhead.
Rather than reusing a generic CUDA Graph flow as-is, LoongForge adapts it for the actual GR00T N1.6 VLA training pipeline: stable, repeated forward/backward compute paths are captured into a CUDA Graph, while logic that benefits from flexibility—such as random-noise sampling and dynamic input handling—stays on the eager path. We also redraw the capture-and-replay boundaries to fit gradient accumulation across multiple microbatches and DDP overlap timing, enabling CUDA Graph to run stably in real multi-GPU GR00T N1.6 training.
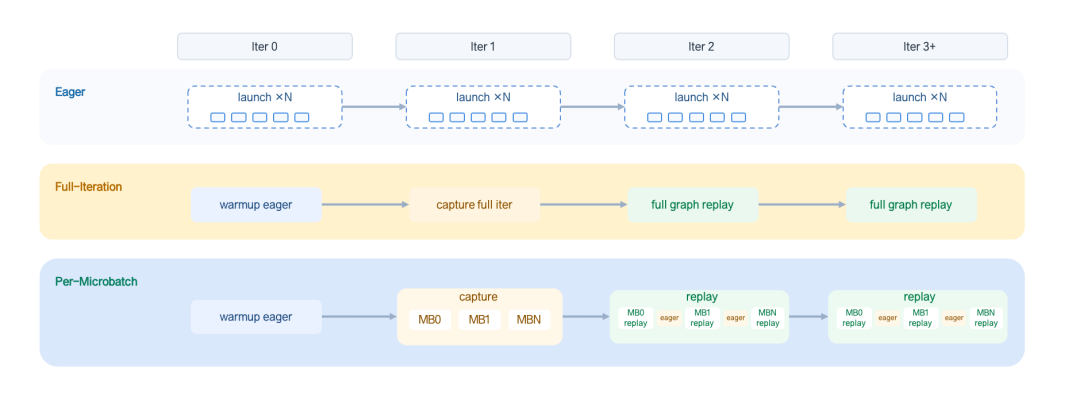
In LoongForge, GR00T N1.6 training keeps three execution paths—Eager, Full-Iteration CUDA Graph, and Per-Microbatch CUDA Graph—each serving a different stage and scenario:
- Eager mode: CUDA Graph is fully off. Used for functional verification, loss alignment, dynamic-graph debugging, and the early stages of integrating new models or new data shapes.
- Full-Iteration CUDA Graph: captures multiple microbatch forward/backward and grad sync within a full iteration into a single CUDA Graph. This minimizes CPU scheduling and kernel launch overhead and is best suited for benchmarking the upper bound of CUDA Graph throughput.
- Per-Microbatch CUDA Graph: pushes capture granularity down to the microbatch level. The capture stage produces smaller, reusable graphs for each microbatch's forward/backward subgraph; the replay stage reuses these graphs in microbatch order, keeping gradient sync logic on the last microbatch so DDP overlap continues to work.
Compared to Full-Iteration, Per-Microbatch is no longer about chasing "a bigger graph" but about "drawing the right boundaries": random-number logic such as beta.sample and torch.randn stays on the eager path, so randomness is not frozen by capture and loss alignment is preserved; gradient sync points stay on appropriate microbatch boundaries, so the CUDA Graph optimization does not break the original communication-computation overlap rhythm.
To make CUDA Graph robust on the real GR00T N1.6 workload, we performed graph-safe refactoring on the vision encoder, language backbone, and action DiT components: static buffer reuse, fixed-shape padding, cached positional encodings and window indices, avoidance of dynamic allocation during capture, and replacement of certain non-capturable operators—so CUDA Graph runs reliably in real multi-GPU training.
With this optimization, GR00T N1.6 training gains close to 1.5× throughput in multi-GPU settings. Per-Microbatch mode keeps performance close to Full-Iteration while offering better loss alignment, providing a more efficient and stable execution path for GR00T N1.6 training.
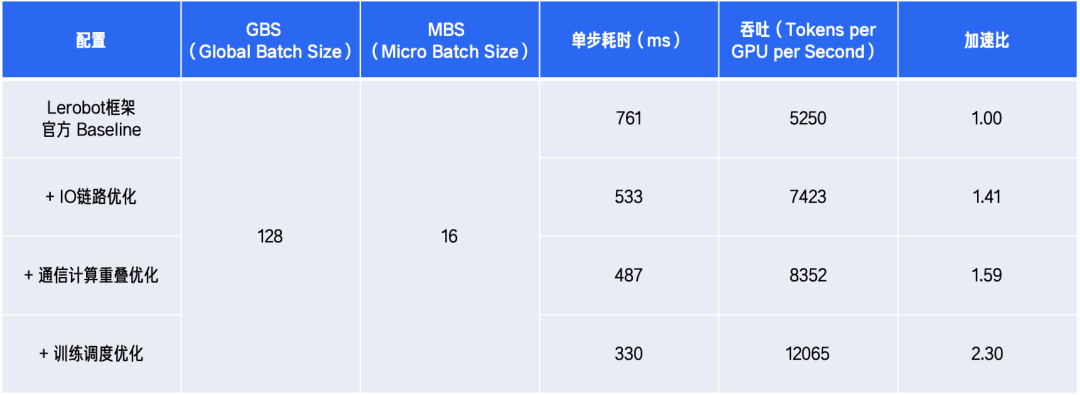
4. Performance results: training cycle halved, time reduced by 56.6%
On an 8×A800 (80G) node, we trained GR00T N1.6 on the Libero dataset. Across the full training task, the overall training cycle is reduced by 56.6%, significantly speeding up model R&D and experimental iteration.
Performance comparison across optimization stages:
5. Summary: raising effective GPU utilization
By applying system-level optimization across training scheduling, communication-computation overlap, and the data IO pipeline, we significantly cut Python scheduling overhead, communication waits, and data-supply idling, moving the GPU from "passive waiting" to "continuous computation". Without changing the model architecture, we deliver 2.3× speedup and a 56.6% shorter training cycle, substantially improving model iteration efficiency and R&D rhythm.
These optimizations are now integrated into the full-modal training framework LoongForge. We welcome researchers and developers in embodied intelligence to explore more efficient VLA training together.